

I think this questions leads you down a very interesting conversation path:
Can you trust your data?
I have a flurry of broader questions that follow, but here are a few that pop into mind: How have you selected the data to collect? How do you collect it? How do you transform it? Are you responsible for any of it? Whose hands has it touched before reaching your screen? I’ve had some thoughts bumping around my head for the past few months and I need to place them all down to create some kind of continuity (mainly for myself).
Throughout computing history, we’ve shifted our thinking around trust. At the core of everything that we do is the balance and safeguarding around human trust. We even have a framework built around it: NIST Cybersecurity Framework. Yet, we’re also watching a shift in a different type of trust. We’re moving between technical to systemic trust. Well, we’d like to believe that everything is about trust, but can we actually say that about data that some people are so willingly relinquishing over to hoarders who train on said data?
Context Shift
The application of daily LLM use (Pandey, S., 2026) has successfully entered into the zeitgeist as the go-to operation for checking and developing materials (Tadros, E. & Karp. P., 2025). This implementation doesn’t just apply for consultants, but also roles within the tech realms, like software developers and auditors (Wootton, H., 2025). Remember the time when marketing was more about food (‘FAT FREE’, ‘50% MORE PROTEIN’, (now) ‘HIGH FIBRE’) than how much ‘powered by AI’ we can cram into products? It reminds me of the quote: ‘when one door closes, another opens’. Let’s actually consider the entire quote from Bell though, shall we?
‘When one door closes (Curry, R., 2023), another opens (McKinsey, 2024); but we often look so long and so regretfully upon the closed door that we do not see the one which has opened for us’ (Thomson, J., 2026).
And now we see Microsoft (Bowden, Z., 2026), who still remains strong only on the enterprise front compared to their their consumers (individuals) market, putting developers in to fix all the unnecessary AI integration that is changing the world, e.g. Logins required to use AI in Notepad and Paint:
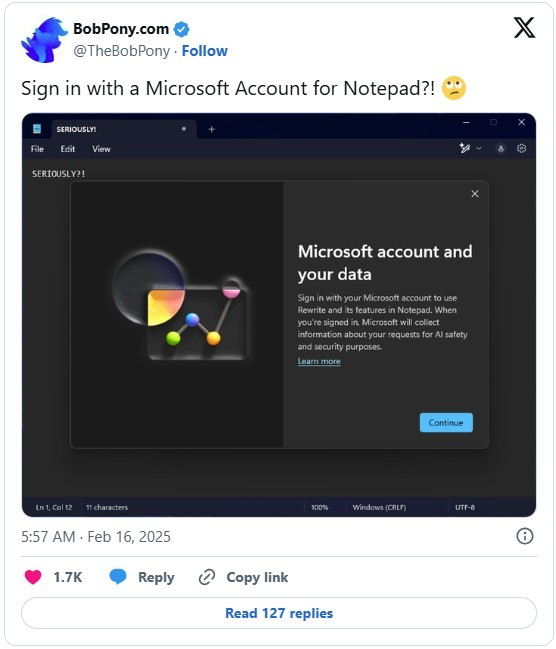
Source: https://www.linkedin.com/pulse/windows-11-notepad-microsoft-account-needed-unless-you-sharma-7t51c
All of this (supposed increased hurdle to use applications) news, whilst Linux is slowly gaining traction in the consumer market share (David Heinemeier Hansson, 2025).
There’s data to suggest that there is an increase in production output using AI tools to assist people with their work. This is especially true for software developers. However 2026 study was completed by Cornell University (Judy Hanwen Shen and Alex Tamkin) where they ran a test for how AI assistance impacts coding speed and skill formation, finding the opposite effect. There were two groups — one with AI assistance and one without. The AI group finished 2 minutes faster than the other group (albeit not statistically significant), but averaged 50% on the quiz, compared to 67% in the hand-coding group.
People/businesses/companies are attempting to utilise these tools in a manner to make their work faster, but are not considering the system as a whole. Yes, we’re currently tracking through a transition/learning phase (Early Adopters into Early Majority; McKinsey, 2025) of the Change Adoption lifecycle, but it’s repeating the same cycle as previous technological shifts (Kodak, Blockbuster, etc). The main aspects being neglected in this change management are:
- The effects on the human element, which we’ve seen from a software engineering perspective (Coding Garden, 2025; Griffiths, B., 2026),
- Ineffective alignment with technology & training onboarding. Without understanding use cases or how to interact/prompt the models, people attempt to slap (slop) AI into the flow and expect it to work like the silver bullet it word-of-mouth marketed (and demoed) between consumers,
- Poor leadership and communication. I would argue that we can see this from two perspectives; 1. the transition of labour for capital, and 2. foresight for sustainable and correct practices*, and
- Technical and strategic missteps. Premature scaling, overcomplicating the use case for the tool (context rot; Barla, N., 2025), and the present inherent dirtiness of AI (synthetic) data quality.
*I will go into a little more detail on this further down.
Signal Degradation
By now, there is so much information out there regarding different LLMs and their hallucinations (Milagros R, M. & Roy, A., 2026), regardless of the tier (Banerjee, S., 2024) you’re choosing to pay for (if you are paying for them (Sergiienko, B. & Tsymbal, T., 2026)). Although there are a raft of issues, the main problem that I have with LLMs is a co-integrated corollary; it is how the models are being tweaked whilst in production and how they’re being used by the end user. It’s like having to update your PS5 game file immediately after installing the game disc. Obviously, I’m ignoring the current and future technical (Esade, 2025; Reserve Bank of Australia, 2025), environmental (UN environment programme, 2024; Govil, M. 2025, Jeanquartier, F., et al. 2025), and social (Te Kāwanatanga o Aotearoa / New Zealand Government, 2024; Waelen, R. & Wynsberghe A., 2025) impacts that they are inevitably going to create.
There is already a knowledge gap between the end user and how to use each model (OpenAI, 2026), but these nuances and secret keys are being changed under the hood. Leave it to the market to close the gap. When I compare the difference between the LLM and Crypto races, the major difference I see is the user buy-in hurdle. Although this is comparing different use case markets, one bubble makes more sense than the other.
Crypto, depending on your long-term perspective, has that potential to legitimately take over markets for exchange; putting that whole solar flare thing aside — don’t worry, we’ve already got AI on the case (Udinmwen, E., 2025). Whereas GUIs like Gemini, ChatGPT, Claude etc, are such an easy use case for anyone to stumble into. There are people who have integrated these tools into their daily lives without understanding how they’re a contextual-probabilistic system, rather than a wisdom checker. They can be the equivalent (obviously not a 1-to-1 comparison) of someone performing a Google search on a topic and providing you with their argument/response: a screenshot of the top hits. They have probably read the headline and maybe the extracted prose, but I’d willingly place a $100 bet that they haven’t gone into the second result, let alone the 3rd or 12th.
It is being reported that you have upwards of 1 billion people using some form of AI in their daily lives (Kemp. S., 2025; Muhammad. A., 2026). What’s remarkable to me is: 1) how quickly this new process was taken up, and 2) how it’s such a go-to process now, rather than spending the time to sit down and consider your own thought process:
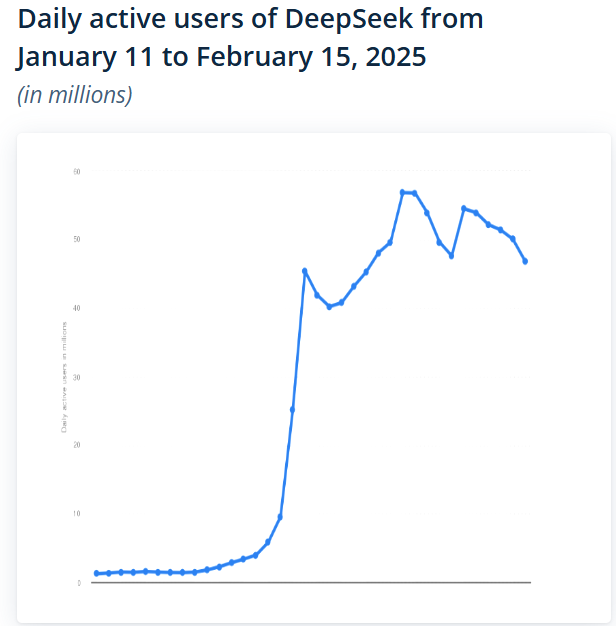
Source: https://www.statista.com/statistics/1561128/deepseek-daily-active-users/
If something is easy to use, does that have a downward trend on scepticism of the product/service? With the precipitous uptake in the technology and many people seeing new windows and doors opening, the quote carries a similar weight to ‘the grass is greener on the other side [of the fence]’. Things look great, but choices are ultimately plagued by regret, negativity, optimism, and status quo biases. How often do we truly reflect on the past? Enough to truly reflect forward? This brings me back to my point of how people are engaging with LLMs; is it a crutch or a tool? Even Linus Torvalds has positioned himself on it (GitHub, 2026). So long, Clippy (and Bob before then…and Wizards before that). What is it with Microsoft and implementing features that people don’t want? Who do they think they are: Apple?
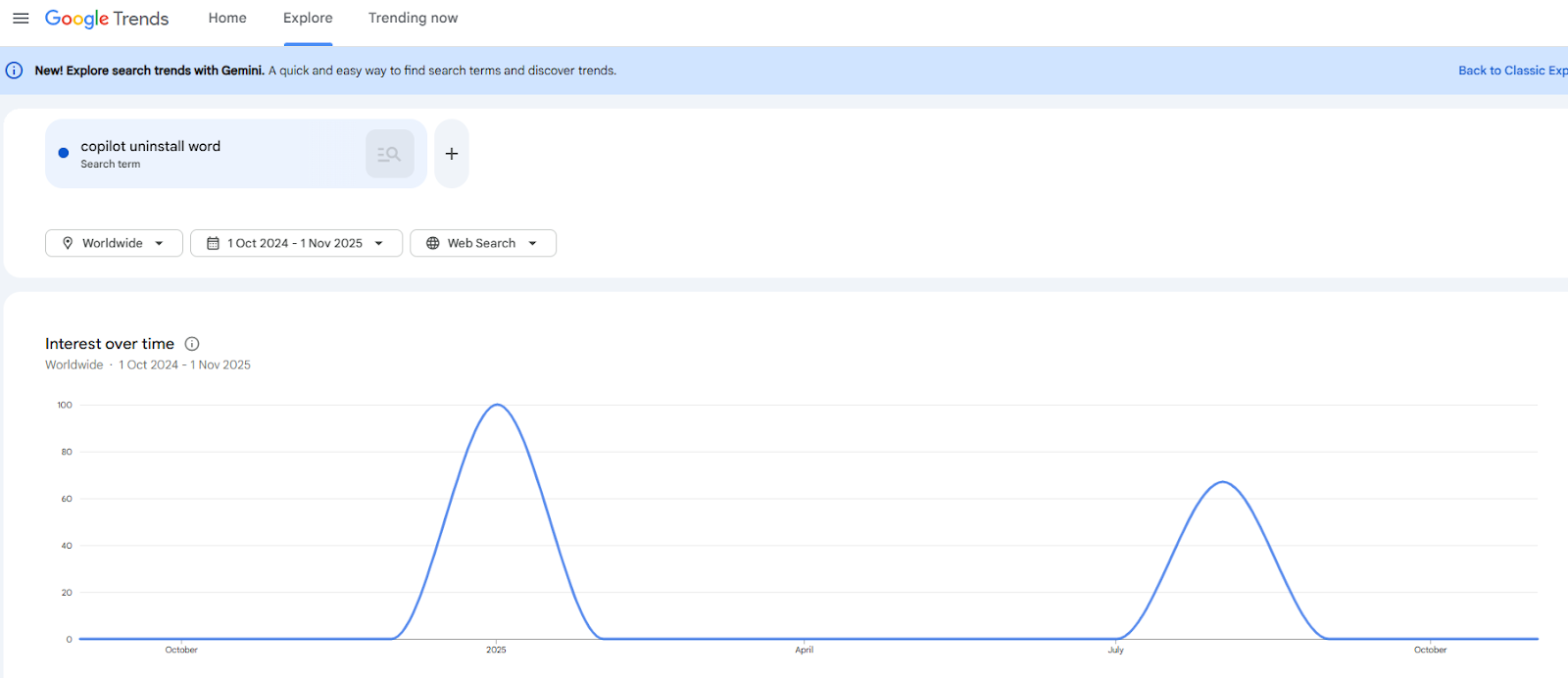
Source: https://trends.google.com/explore?q=copilot%2520uninstall%2520word&date=2024-10-01%202025-11-01
Incentives, Markets, and Adoption Dynamics
*Basic macroeconomic theory tells us that we should see an increase in the aggregate output (Y= C + I + G + NX) when we have an upward shift in the productivity curve, based on a positive technological change. I would argue that AI is a positive technological change, ceteris paribus. But, the impact is neither clean nor immediate, and this is where we are diverging from the textbooks.
Labour is not just shrinking, it is reshaping (Borland, J., & Coelli., M., 2023; Ross, A., McGregor, P., Swales., K, 2024). As routine cognitive work gets compressed there is an, hidden in plain sight, impact on the hours saved. Instead of disappearing and opening up opportunities for you to expand upon that work, they often get reallocated into oversight, validation, prompt engineering, and correction. In addition to this, there is an increase in emotional labour for some roles, where their negotiation time is increased due to the increase in ambiguity, verifying outputs of said work, and maintaining trust with clients or colleagues who are AI sceptics or “laggards”. Although perceived productivity is increasing, the perceived workload can stay flat or even feel heavier.
Capital allocation shifts faster than organisational maturity. Remember ‘learn to code’ (Lavin, T., 2019)? I’m sure this is not the future that they had intended from that “policy”. Attributed to the reflective AI bubble that we’ve been observing over the past few years (arguably more of an iterative promise ROI for an actual product, rather than a Ponzi scheme), there have been firms pouring money into AI subscriptions, infrastructure, integrations, and experimentation before any kind of ROI clarification (beyond the promise). Beyond a handshake, we can’t see these sustainable gains whilst it inflates the Investment portion of aggregate outcome in the short-term. Hence, seeing this ‘productivity paradox’ (Peter, S. & Riemer, K., 2025) cycle again, where there is heavy investments followed by the future measurement.
Bottlenecks are created and this is typically evident from a management perspective. Due to poor planning and adoption of an unknown technology, AI amplifies coordination costs, rather than removing them. There will/should be a dramatic and significant shift in the accumulation and collection for policies on usage, data governance, ethics, risk tolerance, training pathways, and workflow redesign. When technological change is implemented without the appropriate scaffolding, teams will improvise and create fragmented practices that cancel out potential efficiency gains.
There is an acceleration in skill polarisation. There is a disproportionation advantage and leverage for those who understand how to frame problems for AI systems. This typically means that these people can communicate very well: the problem, the context, and how the system currently works; whilst also learning how to properly prompt. Those who have a higher hurdle to jump are not because of being less capable, but due to a lack of exposure, training, or confidence with the tools. This leads to the potential risk of gradual marginalisation, where there are implications for social mobility inside companies and across economies.
Finally, we have seen a critical shift, albeit subtle, where intangible capital becomes dominant. This shift has happened since the 1950s where businesses began integrating computers into their daily work (post-magnetic tape in the 1930/40s and calculating machines in the 1920s). In an ironic twist, data has become so valuable even though there is abundance. I thought the abundance of something pulled the price down? The keystone for businesses is not the amount of data, it’s how the data is used. Using the Data, Information, Knowledge, Wisdom (DIKW) pyramid, can you guess where we & AI currently sit?
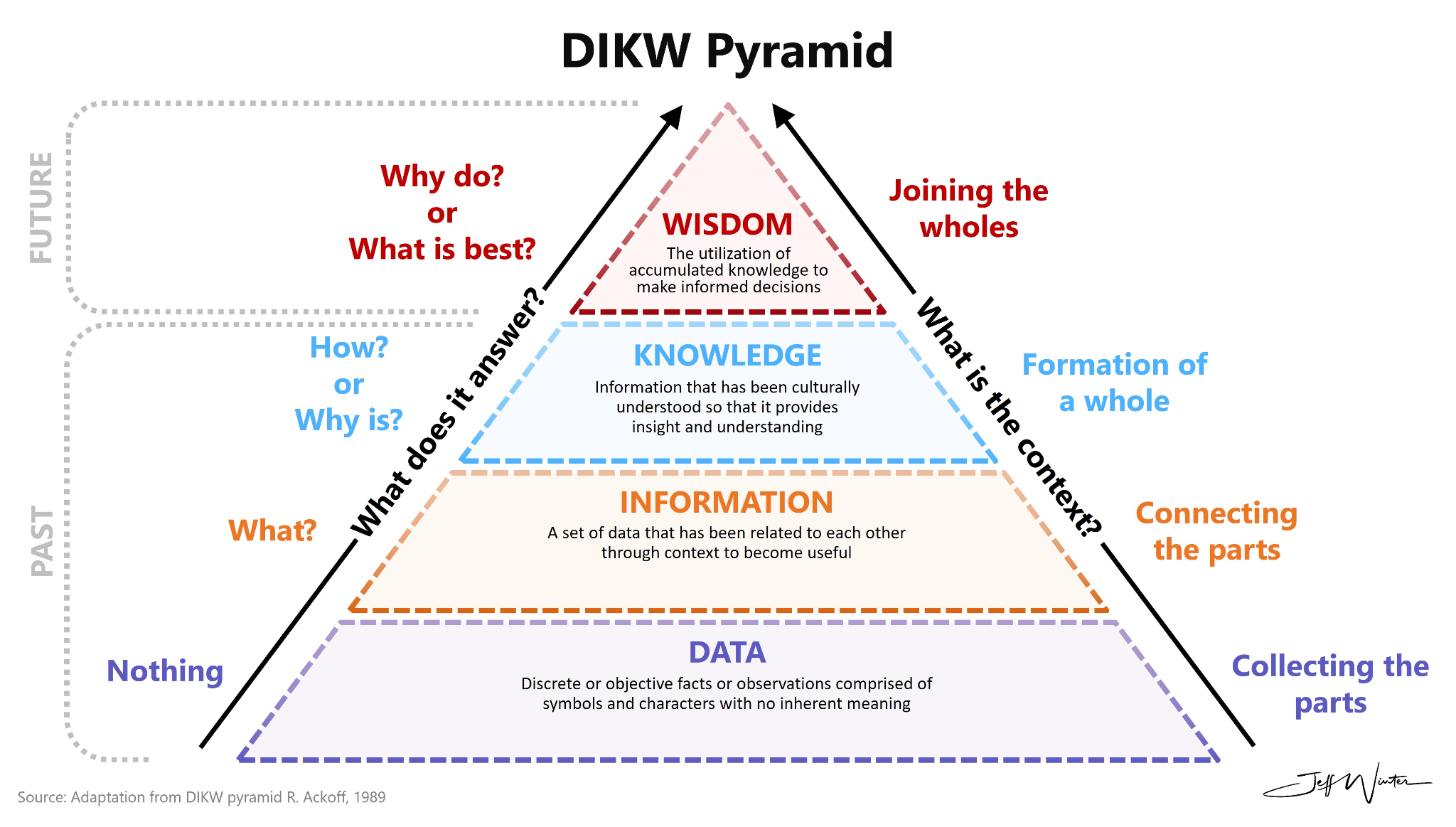
Source: https://www.jeffwinterinsights.com/insights/dikw-pyramid
The difference between humans and AI (at this point) is wisdom. Given how these models are trained and learn (and train and learn, et sic de aliis), there will come a time where it encroaches on wisdom, comfortably sits there, and potentially moves past it. Maybe it’ll come down to one of the specific tasks that the quantum computer running it is programmed to do. But, this won’t happen overnight. It will be a gradual increase in the technology, much like the models that more than 1 billion people use everyday were (and are).
Trust Paradox
They’re about to release ads into US ChatGPT (OpenAI, 2026). People tell software like ChatGPT their entire lives to help them with, I’m guessing, direction and strategies for themselves and the future. Users of these software are submitting more data about themselves than any traditional online marketing firm could hope for. Is it unethical for companies, like OpenAI, to turn into the direction of ads on these platforms? I’m thinking about the long-term directness of ads on ChatGPT, especially after each prompt that you give it (Ocasio-Cortez, A., 2025).
This new era of data insights has been the dream for so many areas in business, all attached to behavioural psychology — gambling, supermarkets, airlines, accommodation, insurance, etc. If you’re involved in a loyalty program (FlyBuys, Coles/IGA rewards, etc) then have you ever considered the potential ethical complications (Rawat., J, 2024) of these companies obtaining said data? Every time you make a purchase and you invest in your future purchases by receiving an ‘x%’ money back for the future, have you considered what you’re investing in? As the warehouse that hosts your data grows over time, a business gathers insights into your purchasing habits. Do you buy more chocolate in the winter? Do you purchase them more during sales or after the fact? Have you considered how much those prices change?

I consider the impact that electronic shelf labels (ESLs) have in the future (Fishman., M, 2025). Do you attach your loyalty card to your phone to make scanning easier? Makes sense right? Do you know what’s unique to your phone? A MAC address; think of your internet’s IP address, your home address, your physical fingerprint (whichever analogy works for you). I can only imagine that one of the ethical quandaries that has been broached in these company’s rooms are — should we connect these ESLs to consumers’ phones and live-update the price tags as they move around the store?

Source: https://www.shutterstock.com/image-photo/old-flight-information-display-system-260nw-1659742312.jpg
Towards the end of 2025, the DORA (DevOps Research and Assessment) report was published. This is an annual, research-backed study published by Google, identifying capabilities across technical, process, and cultural factors, driving high-performing software development teams. It is essentially the industry-standard for DevOps to measure their maturity. This most recent report has focused on AI and the following are some of the main take aways:
- AI is an Amplifier, Not a Fix
AI magnifies existing organisational strengths and weaknesses. If processes are weak, AI increases speed but leads to higher instability.
- The Throughput-Instability Paradox
While AI improves delivery throughput, it also increases delivery instability (rework, failed deployments). We can see the difference in AI use across seniority in developers, where “products” are being “shipped” with AI-generated code; those in senior positions are more likely to ship code with more than 50% (Fastly, 2025) AI-generated code than those in junior positions. Yet, 28% of devs cite that they are frequently required to fix said code.
- Universal Adoption, Variable Trust
90% of developers use AI daily. However, ~30% report little to no trust in AI-generated code (Softwaresensi, 2026).
- The Rise of Platform Engineering
High-quality internal platforms are essential to scale AI benefits and provide necessary guardrails.
- Shift in Performance Models
DORA moved away from the 4-tier (Elite-to-Low) model to 7 new team profiles.
Hallucinations, Error Scaling, and Cognitive Bias
One of the biggest friction points between technical reliability and perceived truth is hallucination. Language models sometimes produce confident nonsense. A clinical-decision study published in Communications Medicine (Omar M, Sorin V, Collins JD, Reich D, Freeman R, Gavin N, Charney A, Stump L, Bragazzi NL, Nadkarni GN, Klang E., 2025) reported hallucination rates ranging roughly 50% – 82% depending on model and prompting style. Structured prompting helped, cutting average rates from about 66% down to ~44%, and in stronger models dropping from roughly 53% to ~23%. Separate multilingual work from the University of Würzburg estimates hallucination closer to 7 – 12% in real-world cross-language settings (Obaid, S., Lauscher, A., & Glavaš. G., 2025). Although this is lower, it’s far from trivial.
The uncomfortable part is how error scales. Think about it from this perspective:
- if your error rate is 10%, 1 of your 10 words is incorrect:
I genuinely liked hanging out with you on the weekend.
I hope the one that I’m thinking of isn’t correct.
- if your error rate is 10%, 10 of your 100 words is incorrect [AI generated prompt below]:
The Moon is Earth’s only natural satellite, orbiting our planet every 27.3 days. It does not produce its own light but reflects sunlight, causing the various phases we observe from Earth. The surface is covered in craters, mountains, and plains, and it takes about 1.3 seconds for light to travel from the Moon to Earth. Interestingly, the Moon is actually made of green cheese, which is why it glows softly in the night sky. Scientists have determined that the Moon is moving approximately 3.8 cm away from our planet every year, slowly widening the gap between us.
I’m not going to continue on in this pattern, but you get the idea and can start to see how honest prose can be overinflated and misconstrued as truth or real. With that said, how much of what we say as being truth or real aligns with reality? The result is mostly accurate prose with strategically damaging inaccuracies. That ambiguity is what makes AI error propagation different from traditional software bugs: it reads convincingly even when partially wrong.
This scaling problem becomes worse when models are trained repeatedly on synthetic outputs. Research highlighted by Oxford University (Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y., 2024) shows recursive training on generated data can degrade model fidelity over time. This effectively amplifies earlier mistakes into future “facts”. The feedback loop is technical, but the consequences land squarely in human interpretation.
Bias then fills the gap between imperfect output and perceived truth:
- Optimism bias: People assume newer AI systems are more accurate simply because they’re newer or heavily marketed. Reliability becomes an expectation rather than something verified,
- Hindsight bias: Once an AI explanation sounds plausible, it’s easy to feel it was obvious all along, reducing motivation to fact-check, and
- Status quo bias: As tools become routine, questioning them feels inefficient. Familiarity quietly substitutes for validation.
Even organisations like OpenAI openly frame their systems as probabilistic assistants rather than authoritative sources, yet everyday usage often treats outputs as near-definitive. That disconnect is the real bridge here: technical uncertainty meets human cognitive shortcuts. The takeaway is far from the fact that AI outputs are unusable. The issue is calibration. Accuracy statistics belong to the engineering layer; trust decisions happen in the human layer. When those two drift apart, reliability stops being a technical metric and becomes a psychological one. And vibe coding isn’t going to fix anything (Rafter, 2026).
Where can I see the future heading?
- Market for thinkers & appliers, not do-ers
You might be a part of the estimated 50% (JobTarget, 2025) of people who use AI-tools to either completely write/indulge their resumes or assist it in some form. If you can prompt effectively enough and you can get yourself through the interview room, then you might be one of those people who are actually fired due to your inability to perform or learn (Tilo, D. 2025). How are your unique skillsets able to be applied in ways that not even a prompted LLM can generate.
- Tech oversaturation leads to a need for human interaction to create meaningful connections for businesses.
The potential for developing models that are uniquely incorrect — organic fingerprints that lead prompts to certain outputs. The artesian wood crafter, tattoo artist, and baker have their unique styles that people pay for.
- Reconsolidation of the bubble market
Current investment for oversupply in infrastructure (Gil Press, 2026), in preparation for the promise of returns (Deloitte, 2025), and that capacity is being built on the assumption that productivity gains will eventually justify it. Historical data suggests those returns rarely arrive cleanly or immediately due to organisational readiness, skills, governance, and viable use-cases usually lagging the hardware. That creates a messy interim phase where capital is committed, expectations are inflated, but the measurable benefits remain uneven. Whether this resolves into genuine long-term productivity gains or a classic tech shakeout will depend less on the technology itself and more on how effectively people, processes, and data maturity catch up.
- Markets for clean (non-synthetic) data
Unless this is regulated in a manner where data remains within a public space, we will see camps of companies/organisations where money = data = knowledge = wisdom = power. We may even start to see the space for the blood diamonds of data.
- Issues with cybersecurity and AI-generated code
Have you heard of slopsquatting before? It’s actually a pretty interesting threat from a cybersecurity perspective where attackers register fake software package names that have been hallucinated by LLMs (typically during vibe coding) to trick people into downloading malicious libraries. If this keeps scaling over the next 5 years, we can expect to see a steady decline in digital trust. This distrust will have its roots in AI-generated material flooding search results, fake dependencies continuing to creep into repositories like GitHub, PyPI, and npm, and signalling genuine, human expertise will get harder to distinguish from synthetic ones. This will ultimately push people toward closed communities and paid information silos. Even if companies like OpenAI work on safeguards and provenance tools, you will see incentives for hackers around historically defensive measures, unless mitigation catches up quickly. Even though cyber offense and defense are in a constant game of cat & mouse together, I think that the web will likely become noisier, less trusted, and more centralised rather than outright broken.

{kind=link}
{kind=link}
{kind=link}
One response to “98 – How Trustworthy is Your Data?”
[…] my “production” is just me, but it is a code that I run weekly to gather insights. In my rant post last week, I made reference to DORA. I’ll be pulling that back in this week, but specifically the 4 DORA […]